API: Como obter informações de consumo em conteúdos
 Atualizado
por
Larson Guimarães
Atualizado
por
Larson Guimarães
Como obter informações de consumo de conteúdos
A API do Learning.Rocks dispõe de endpoints para obter informações de consumo dos conteúdos. Clicando aqui você pode acessar a collection completa de consumo em contents.
Informações que podem ser obtidas:
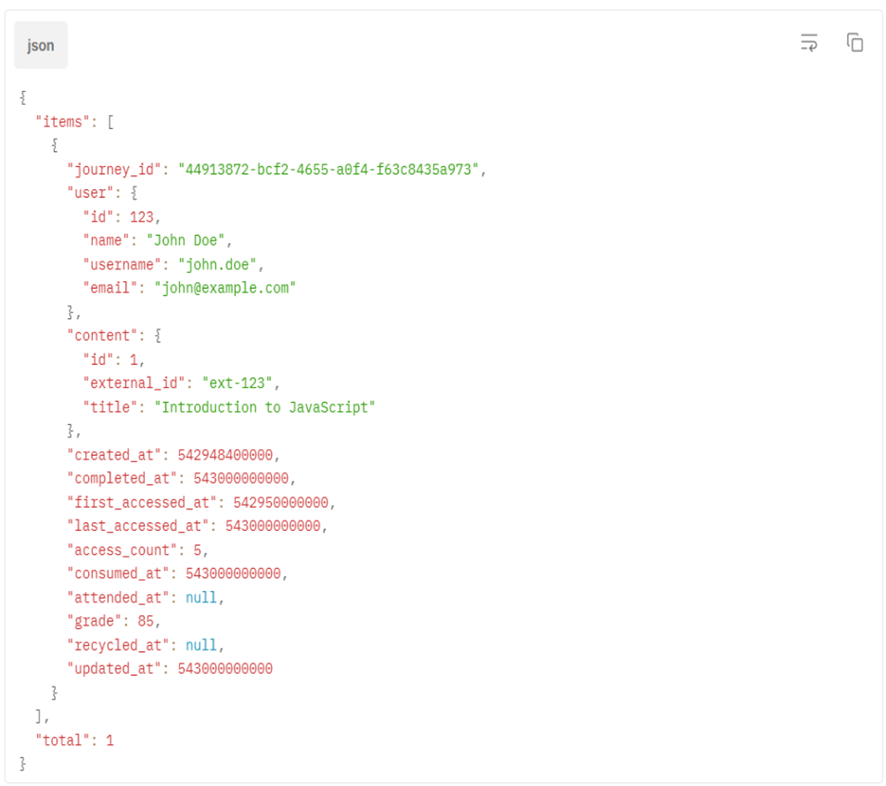
- Journey ID;
- Dados do usuário (ID, nome, username e e-mail);
- Dados do conteúdo (ID, titulo e external ID);
- Data de criação do conteúdo
- Data de completude;
- Data de consumo;
- Data de presença;
- Data do primeiro acesso ao conteúdo;
- Data do último acesso ao conteúdo;
- Quantidade de acessos ao conteúdo;
- Nota;
- Data de reciclagem do conteúdo;
- Data de atualização.
Construindo a consulta
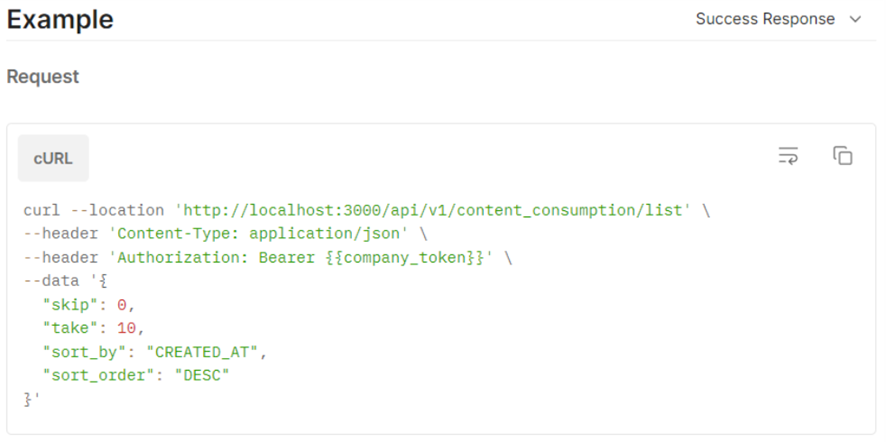
Para buscar o conteúdo a partir do ID, é necessário enviar o comando POST para a URL: https://consume.learningrocks.io/api/v1/content_consumption/list
Parâmetros
- Users (array, opcional): Array de IDs de usuário, e-mails ou nomes de usuário. Máximo: 100 itens. A API pesquisará usuários que correspondam a qualquer um dos identificadores fornecidos dentro da empresa;
- content_ids (array, opcional): Array de IDs de conteúdo para filtrar. Máximo: 100 itens;
- date.type (string, obrigatório se min ou max for fornecido): Tipo de campo de data para filtrar. Valores possíveis: CREATED_AT, UPDATED_AT, COMPLETED_AT, FIRST_ACCESSED_AT, LAST_ACCESSED_AT, CONSUMED_AT, ATTENDED_AT, RECYCLED_AT;
- date.min (número, opcional): Filtro de intervalo de data usando timestamps Unix em milissegundos. Esse parâmetro define a data mínima para filtrar o consumo de conteúdo;
- date.max (número, opcional): Filtro de intervalo de data usando timestamps Unix em milissegundos. Esse parâmetro define a data máxima para filtrar o consumo de conteúdo;
- grade.min (número, opcional): Filtro de valor mínimo para filtrar o consumo de conteúdo com base na faixa de nota obtida pelos usuários;
- grade.max (número, opcional): Filtro de valor máximo para filtrar o consumo de conteúdo com base na faixa de nota obtida pelos usuários;
- skip (número, opcional): Parâmetro de paginação para controlar o número de registros retornados. Define o número de registros a serem ignorados (deslocamento);
- take (número, opcional): Parâmetros de paginação para controlar o número de registros retornados. Define o número máximo de registros a serem retornados (limite);
- sort_by (string, opcional): Campo para ordenar os resultados. Valores possíveis: CREATED_AT, UPDATED_AT, COMPLETED_AT, FIRST_ACCESSED_AT, LAST_ACCESSED_AT, CONSUMED_AT, ATTENDED_AT, RECYCLED_AT.
- sort_order (string, opcional): Direção da ordem de classificação. Aceita ASC para ordem crescente ou DESC para ordem decrescente.
Pontos importantes
Para lidar com um grande número de solicitações simultâneas, garantindo que o desempenho não seja comprometido, recomendamos que as solicitações sejam sempre feitas de forma paginada. Use os parâmetros skip e take para implementar a paginação e evitar o carregamento de quantidades excessivas de dados em uma única solicitação.
- Os parâmetros de filtro são opcionais e podem ser combinados para criar consultas complexas.
- Os arrays users e content_ids têm um tamanho máximo de 100 itens cada. Solicitações que excedam esse limite resultarão em um erro de validação.
- Se o parâmetro users for fornecido e nenhum usuário correspondente for encontrado na empresa, a API retornará uma lista vazia (itens: [], total: 0) em vez de um erro. Isso permite o tratamento adequado de identificadores de usuário inválidos.
- Ao especificar os parâmetros date_min e date_max para filtrar por intervalo de datas, também será obrigatório especificar o parâmetro date_type.
- Pelo menos um dos parâmetros date_min ou date_max deve ser fornecido quando date_type for especificado.
- O valor de date_min não pode ser maior ou igual ao valor de date_max do período.
- O valor de date_max deve ser estritamente maior que date_min quando ambos forem fornecidos.
- Quando sort_by e sort_order não forem informados, a ordenação padrão será por CREATED_AT DESC (do mais recente para o mais antigo).
- Os parâmetros skip e take devem ser números não negativos. Os valores padrão são skip = 0 e take = null (sem limite) se não forem especificados.
- O filtro de datas suporta diferentes tipos de data que correspondem a vários eventos no ciclo de vida do consumo de conteúdo:
- CRIADO_EM: Filtra por quando a jornada do usuário com o conteúdo foi criada.
- ATUALIZADO_EM: Filtra por quando a jornada do usuário foi atualizada pela última vez (para quando o usuário realizar novas tentativas em conteúdos do tipo exame ou com atividade (questões associadas) até atingir a nota mínima ou acabar as tentativas disponíveis).
- COMPLETADO_EM: Filtra por quando o conteúdo foi completado pelo usuário.
- PRIMEIRO_ACESSO_EM: Filtra por quando o conteúdo foi acessado pela primeira vez.
- ÚLTIMO_ACESSO_EM: Filtra por quando o conteúdo foi acessado pela última vez.
- CONSUMIDO_EM: Filtra por quando o conteúdo foi consumido pelo usuário.
- PARTICIPADO_EM: Filtra por quando o usuário participou do conteúdo (para aulas presenciais ou ao vivo).
- RECICLADO_EM: Filtra por quando o conteúdo foi reciclado pelo usuário.
Atualmente, o endpoint retorna informações abrangentes sobre o consumo de conteúdo, incluindo registros de data e hora para vários eventos (criação, completude, acesso, consumo, presença, reciclagem) e notas do usuário. Todos os registros de data e hora são retornados em milissegundos. A resposta inclui metadados de paginação (total) que indicam o número total de registros que correspondem aos filtros, independentemente dos limites de paginação. Isso permite a implementação de controles de paginação adequados e exibam contagens de registros precisas para os usuários.
Exemplo de request e response: